

重點文章
iPhone X 採用了 Face ID,取代 Touch ID 成為新一代蘋果生物識別技術,但是經過那麼多年,蘋果為何會在嚴重「落後」於 Android 手機的情況下,花了這麼多時間開發 Face ID?而且這個 Face ID 還要不斷學習才能準確?
蘋果最近在自家建立的 machinelearning.apple.com 發佈一篇論文《An On-device Deep Neural Network for Face Detection》,以「學術」角度解釋 Face ID 的來龍去脈。留意的是,這篇論文涉及很多深度學習、電腦神經網絡等高深的名字,沒有相應 AI 或電腦神經網絡的知識,恐怕也是讀不懂這篇論文,但為了令各位讀者甚至小編自己暸解有關 Face ID 背後運作原理,小編只能從有限度知識,解讀整個 Face ID 暗地裡正在做什麼。

蘋果最早的臉部識別技術是通過一種名為 CIDetector 實現,當時蘋果運用並改進了一種名為「維奧拉-瓊斯目標檢測框架」的靜態圖像識別技術,建立臉部識別,但自從「深度學習」這東西出現之後,蘋果由此獲得啟發,於是轉而引入了「深度學習」計算方法於臉部識別之中,但是以本機作「深度學習」,對於記憶體、儲存空間和圖像處理的要求極高,就像一款大型 3D 遊戲一樣,容易用盡手機系統資源甚至令手機發熱。如是者,不少人會想到用雲端臉部識別取代,但用上雲端,數據有被偷取的可能。基於蘋果過往採用 Touch ID 的經驗,Face ID 臉部識別數據只會在本機儲存,蘋果不會以雲端方法建立 Face ID。
結果,蘋果在開發臉部識別進而開發 Face ID 的時候,總結出可以解決在 iPhone X 本機深度學習臉部的方法,並指出一些要求,例如必需建立多層大型照片庫、用極短時間運行以及減少耗用系統資源令手機不發熱。

事實上,蘋果從 iOS 7 開始引入了一種名為 CIDetecor 的臉部識別工具,但當時的臉部識別並不準確,於是蘋果沒有用它作臉部解鎖或購物之用,但在 2014 年,蘋果開始研究深度學習的時候,工程師留意到一種名為 OverFeat 的深度卷積神經網絡(DCN)方案,實現以不同解像度(例如 32×32)之下作出大量輸入預測,於是蘋果為此創立了一個又一個以固定大小的圖像組成的大數據集,內裡利用 5 個以不同解像度檢測的圖像「金字塔」、人臉檢查器以及事後處理模組共 3 個部分,一層又一層收集和處理臉孔。
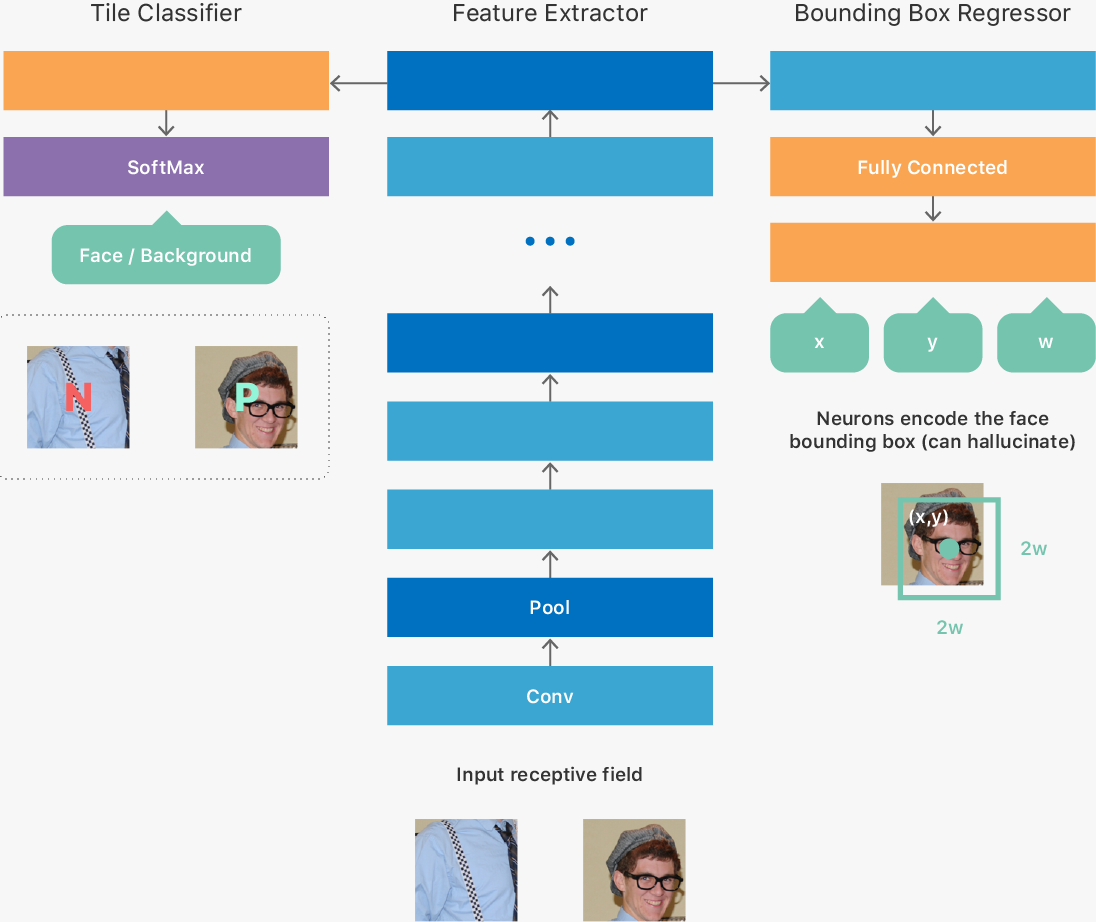
與此同時,蘋果以一種類似「師生」的形式,一層又一層「培訓」出又大又複雜而且又精準的臉部網絡模型,這可能是為 Face ID 需要「學習」,而且不停成功解鎖才能更準確的最重要原因。
而臉部識別的深度學習亦提供了一個視覺框架(Vision Framework),它用來分辨在不同角度、縮放、顏色轉換的臉部數據,蘋果以部分二次採樣解碼技術和自動平鋪技術解決在不同角度、縮放之下在大圖像處理臉部數據的問題,並以更廣的色彩空間 API 分配顏色,減少第三方開發者的負擔。
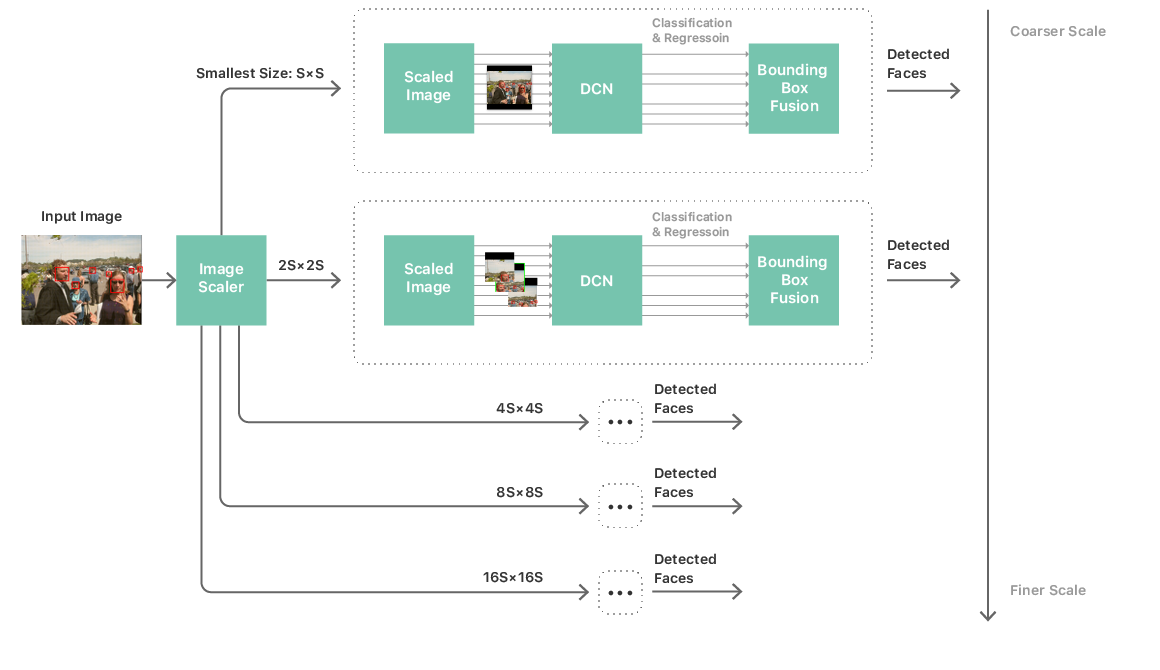
至於如何減少因臉部識別帶來的大量系統資源消耗問題,蘋果為眾多的圖像「金字塔」建立了一個緩衝區,並建立更靈活的記憶體優化計算方法,並將擷取的圖像以動態調整形式調校解像度大小,盡可能減少記憶體和圖像處理單元使用,避免影響其他 App 執行。

Comments are closed.