
Meta 旗下的生成式人工智能副總裁 Ahmad Al-Dahle,今日透過 X 宣佈發佈 Llama 3.3。Llama 3.3 是 Facebook、Instagram、WhatsApp 及 Quest VR 母公司所推出的最新開源多語言大型語言模型(LLM)。Al-Dahle 表示:「Llama 3.3 在核心效能上有所提升,且成本顯著降低,使整個開源社群都能輕鬆使用。」
效能媲美 405B 參數型號
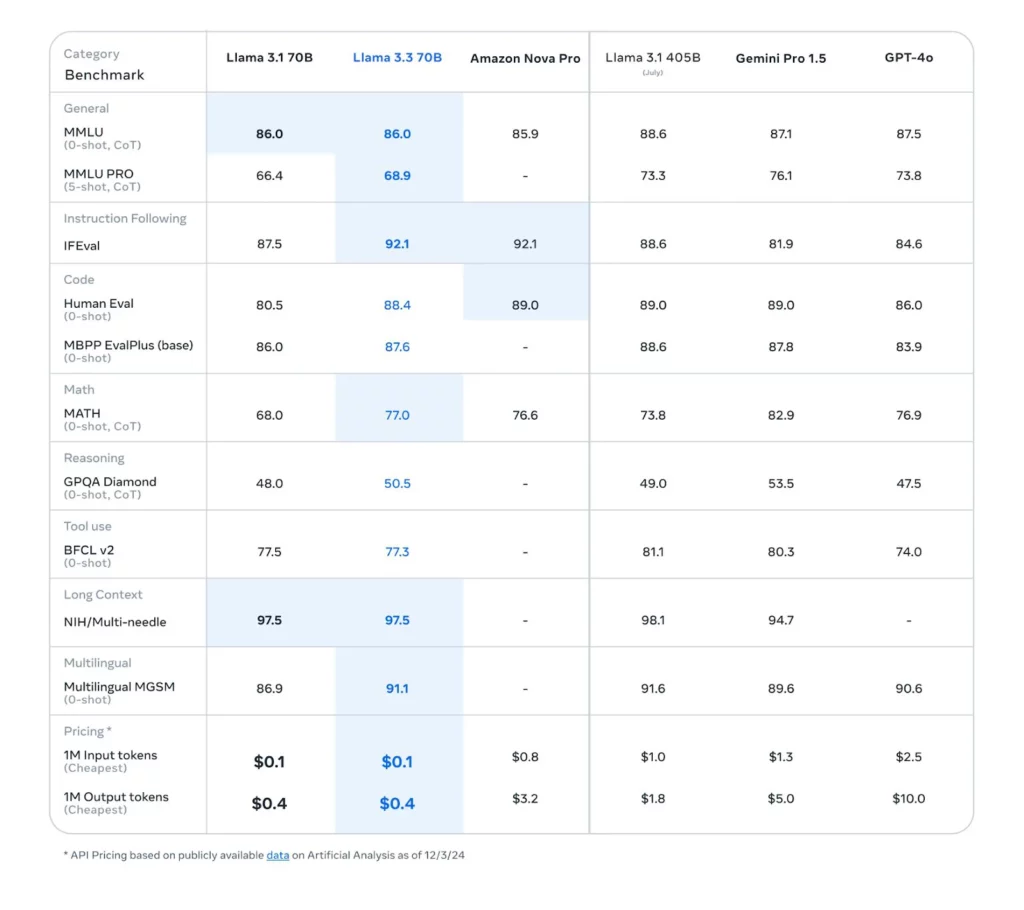
Llama 3.3 擁有 70 億參數,能在推理階段達到與 Llama 3.1-405B 型號相當的效能,但所需成本及運算負擔大幅減少。Llama 3.3 設計著重高效能與可及性,在精簡模型大小的同時,依然維持一流表現。根據 Meta 團隊的說法,這一模型在文本處理方面表現出色,且推理成本僅為過去型號的一小部分。
開源授權與使用限制
Llama 3.3 依照「Llama 3.3 社群授權協議」發佈,允許非專屬、免版稅的使用、複製、分發及修改。開發者需在產品中標註「Built with Llama」,並遵守「可接受使用政策」,禁止產生有害內容、違法行為或支援網路攻擊等用途。對於每月活躍用戶超過 7 億的企業,則需直接向 Meta 申請商業授權。
大幅降低 GPU 運算需求與成本
根據 Substratus 的數據,Llama 3.1-405B 需要 243 至 1944 GB 的 GPU 記憶體,而舊款的 Llama 2-70B 僅需 42 至 168 GB。如果 Llama 3.3 也遵循相似的 GPU 記憶體節省趨勢,將能大幅減少部署時的運算資源需求。例如,部署在標準 80 GB 的 Nvidia H100 GPU 上,GPU 負載可能降低 24 倍,節省高達 60 萬美元的 GPU 採購成本與持續電力開銷。
多語言推理與效能表現卓越
Llama 3.3 在多語言推理方面表現出色,於 MGSM 基準測試中達到 91.1% 的準確率,支援包括德語、法語、義大利語、印地語、葡萄牙語、西班牙語、泰語及英語等語言。此外,在多項基準測試中,Llama 3.3 超越同樣規模的 Llama 3.1-70B 及 Amazon 的 Nova Pro 模型,尤其在多語對話及推理任務中表現突出。
15 兆字元預訓練與能源效率
Meta 表示,Llama 3.3 透過 15 兆個「公開可用」的字元資料進行預訓練,並在 2500 萬筆合成數據上進行微調。整個模型開發耗費約 3930 萬 GPU 小時,充分展現 Meta 對能源效率及永續發展的承諾。