
OpenAI 宣布,從今天起正式將 Sora 的影像生成功能整合進 ChatGPT,這項新功能被命名為 4o Image Generation。過去用戶必須透過獨立網站才能使用 Sora,現在則能直接在 ChatGPT 中生成高品質圖像,操作更加方便。

全新升級的圖像體驗
Sora 最初是作為一款 AI 影片生成工具發表,不過這次首波整合僅針對靜態圖像生成。這項功能將開放給所有 ChatGPT 用戶,包含 Plus、Pro、Team 以及免費用戶。根據 OpenAI 發言人表示,免費用戶的使用次數將與 DALL·E 相同,目前估計為每日三次,但這個數量未來可能會依照需求變動。
圖像正確性大突破
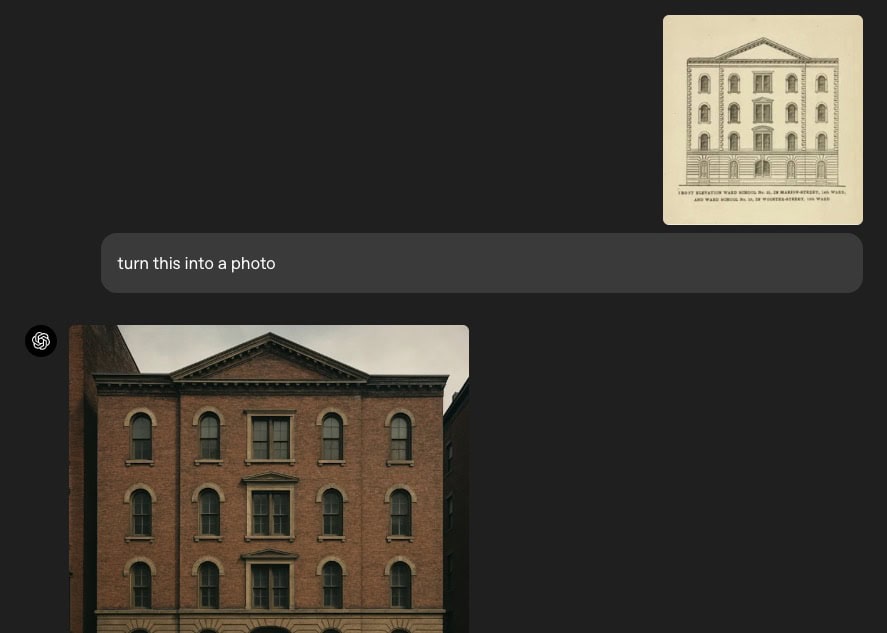
Sora 新版的最大亮點之一,就是解決了長久以來困擾圖像生成器的「綁定」問題。所謂綁定,指的是 AI 在生成圖像時能否正確對應屬性與物件的關係。例如輸入「藍色星星與紅色三角形」,舊型號可能會出現顏色與形狀錯配的狀況。根據 OpenAI 研究負責人 Gabriel Goh 表示,Sora 現可正確處理多達 15 至 20 個物件,遠超過現有的 5 至 8 個極限,準確性與穩定性明顯提升。
這個版本也搭載 GPT-4o 的「omnimodal」核心,意味著它是建立在可同時處理文字、圖像、音訊與影片的基礎上打造的,展現 OpenAI 對於全方位生成能力的佈局。
文字渲染品質顯著提升
另一項重大進步則是在圖像中文字渲染的精確度。許多圖像生成工具在文字處理上仍會出現拼字錯誤或亂碼,讓原本用來製作貼紙、海報、菜單的圖片變得無法使用。Goh 指出,這部分經過數月細緻調整,終於達到穩定輸出的標準,雖仍在極小字體上略有誤差,但整體已足以應用於實際場景。
這也得益於 Sora 採用的「自回歸式生成方法」,即圖像是從左到右、從上到下依序繪製,與大多數一次性生成整張圖的擴散模型相比,能提供更好的細節控制與準確性。

具備世界知識
在發佈前的示範中,團隊展示了包括牛頓三稜鏡實驗圖、連環漫畫角色一致性的表現、資訊海報等多樣應用情境,顯示這項技術不僅能畫圖,更懂圖背後的知識邏輯。

ChatGPT 多模態產品負責人 Jackie Shannon 表示,Sora 的影像生成不僅靠畫功,而是結合了整個世界的知識底蘊,使用者無需過度解釋即可產出符合預期的圖像。
生成速度略慢
雖然目前圖像生成的速度比過去稍慢,但 OpenAI 強調這是為了品質所做出的權衡。Shannon 表示:「雖然在延遲方面還有進步空間,但這些圖像的品質與世界知識涵蓋,絕對值得等待那幾秒。」

值得注意的是,Sora 目前生成的圖片不會添加視覺浮水印,但會內嵌 C2PA 標準中繼資料以標示來源,並由內部工具進行追蹤。同時,用戶將擁有圖像的完整使用權,僅需遵守平台使用政策即可自由應用。